Exercise: Normalizing¶
The Reader Toolbox takes sets of narrative text as input, and it outputs sets of extracted features. As detailed in another section of the documentation, these extracted features include: bibliographics, parts-of-speech, named-entities, email addresses, URLs, an statistically significant keywords. The features have been saved as tab-delimited files as well as reduced to an SQLite relational database file. Thus, analysis against a study carrel can be done through Toolbox commands, through various application programmer interfaces, or through any number of graphical user interface (GUI) applications. A free and cross-platform application called OpenRefine is one such GUI application, and this section outlines how to exploit it for the purposes of using and understanding any carrel.
Keywords¶
Let’s use OpenRefine to address the question, “What are Homer’s works about, and how is this aboutness manifested over the corpus?”. To address this question, we can analyze the files in the wrd directory, where the keyword files are saved. Here’s how:
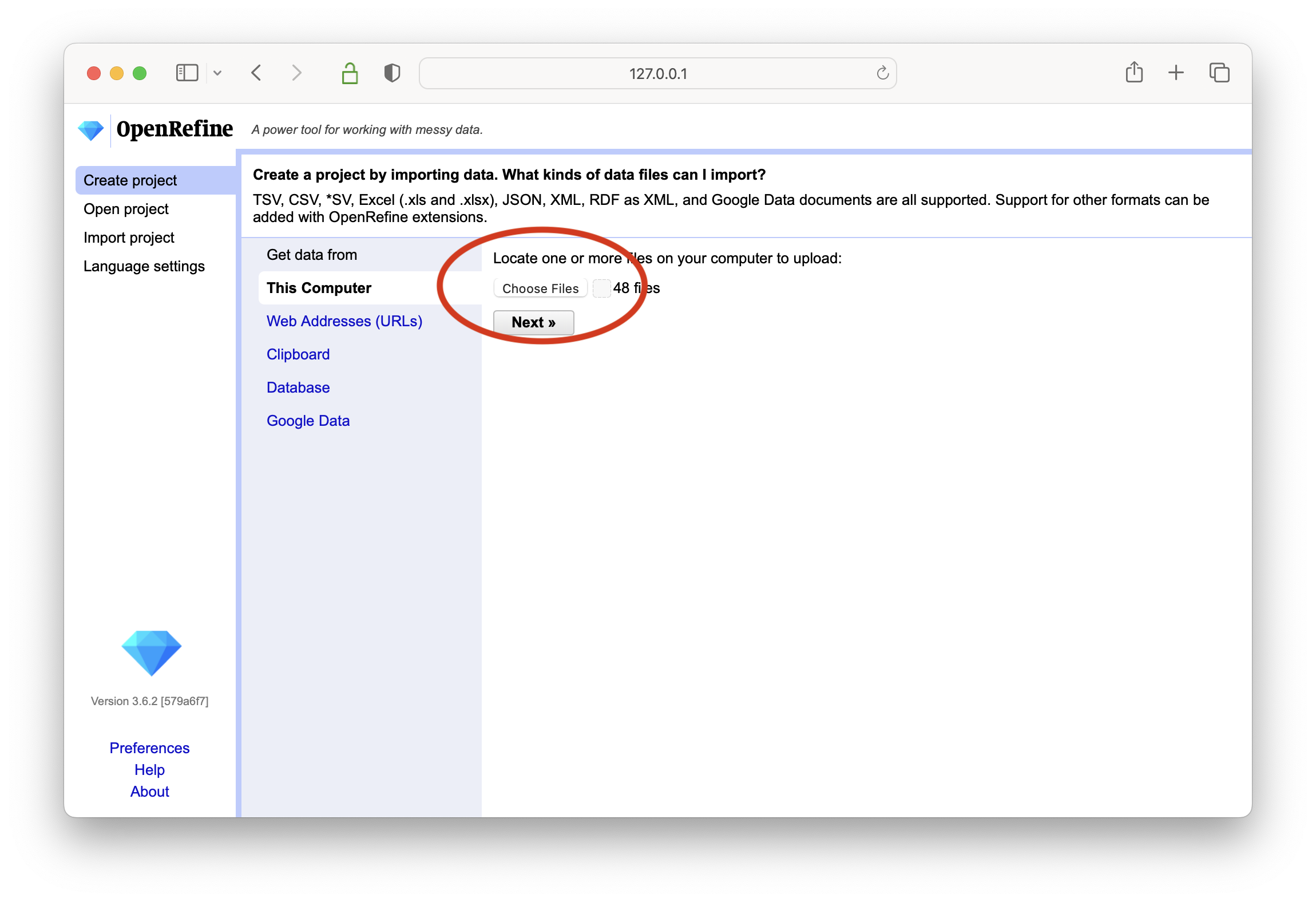
download, install, and lauch OpenRefine
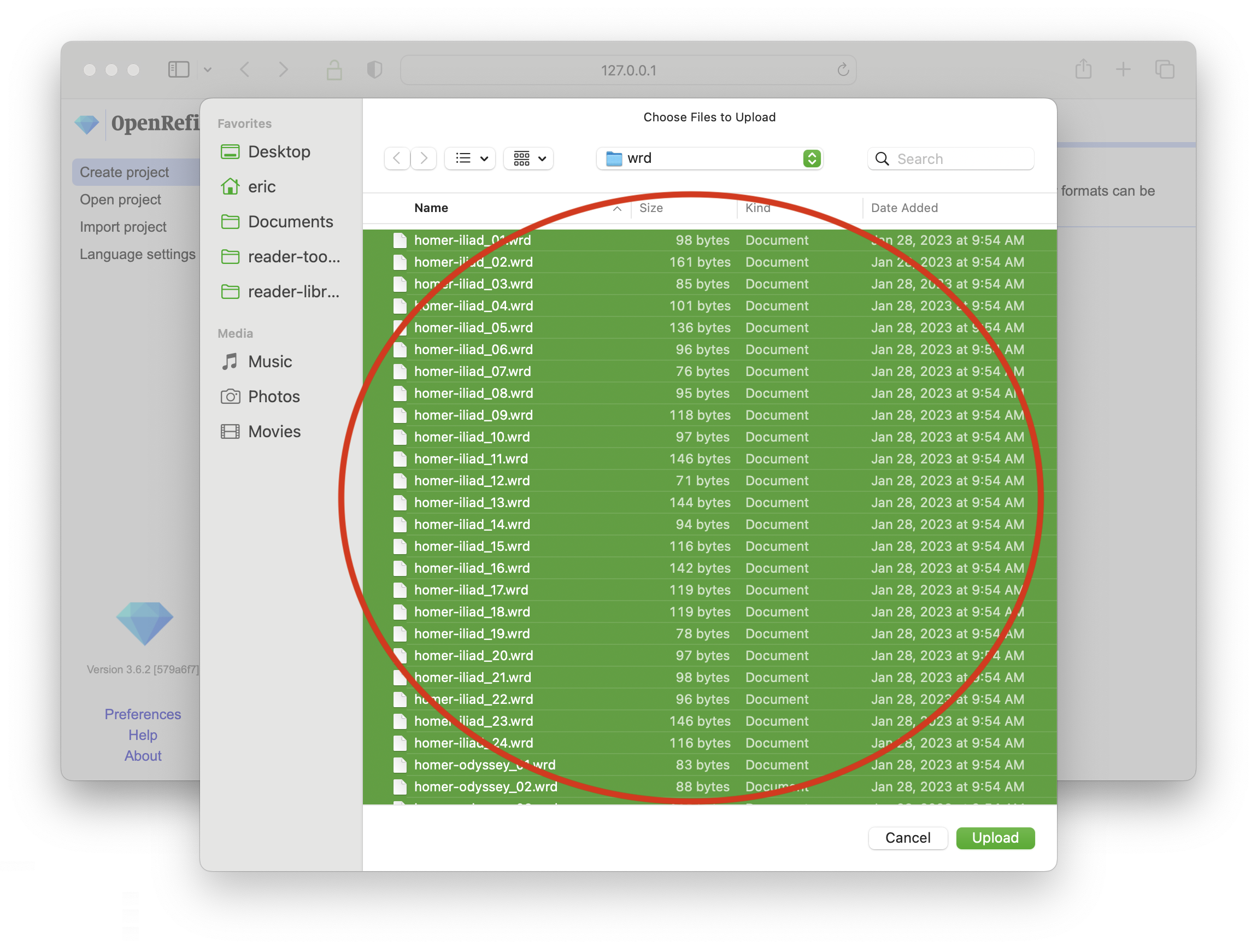
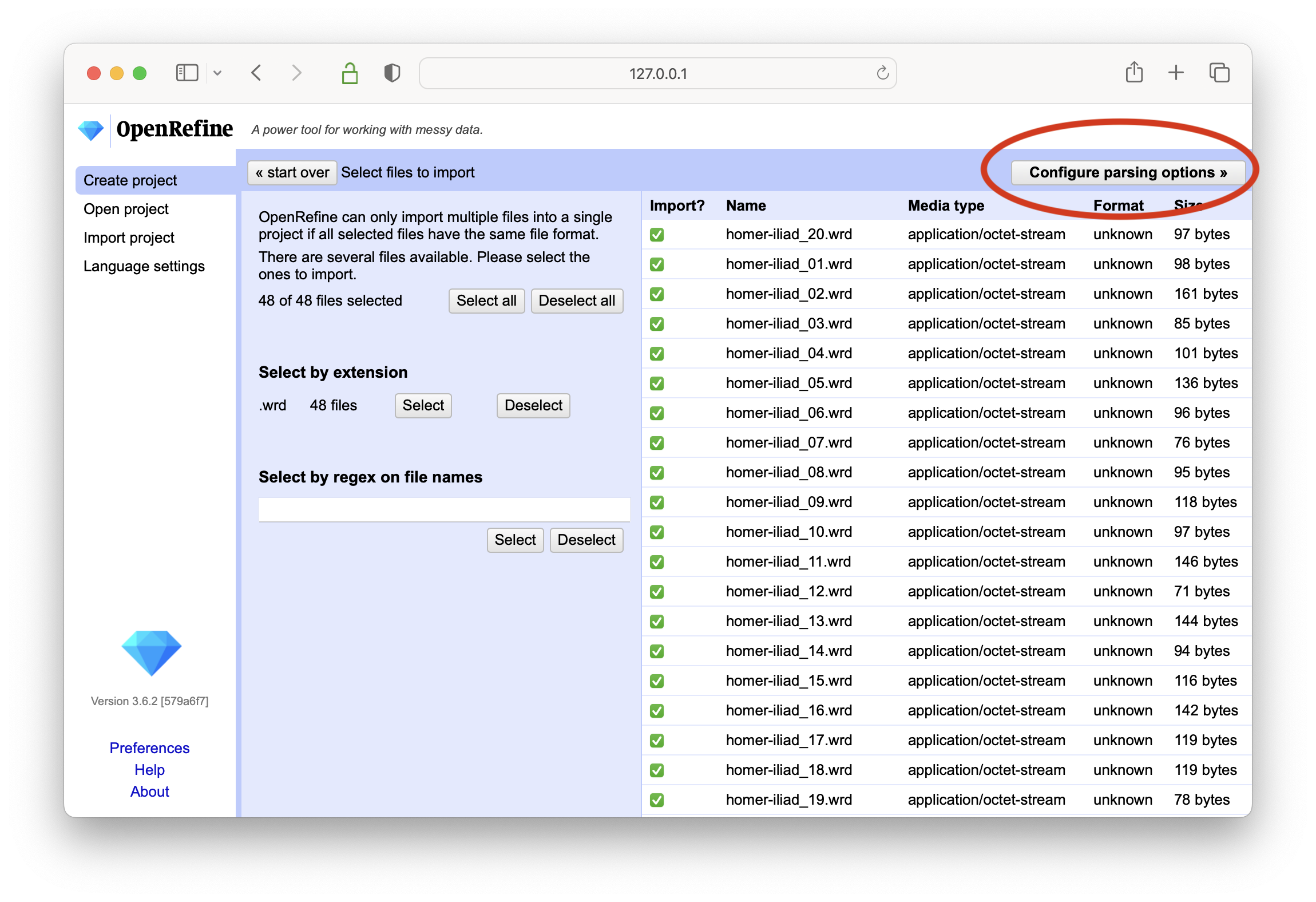
choose all 48 files from the homer study carrel wrd directory
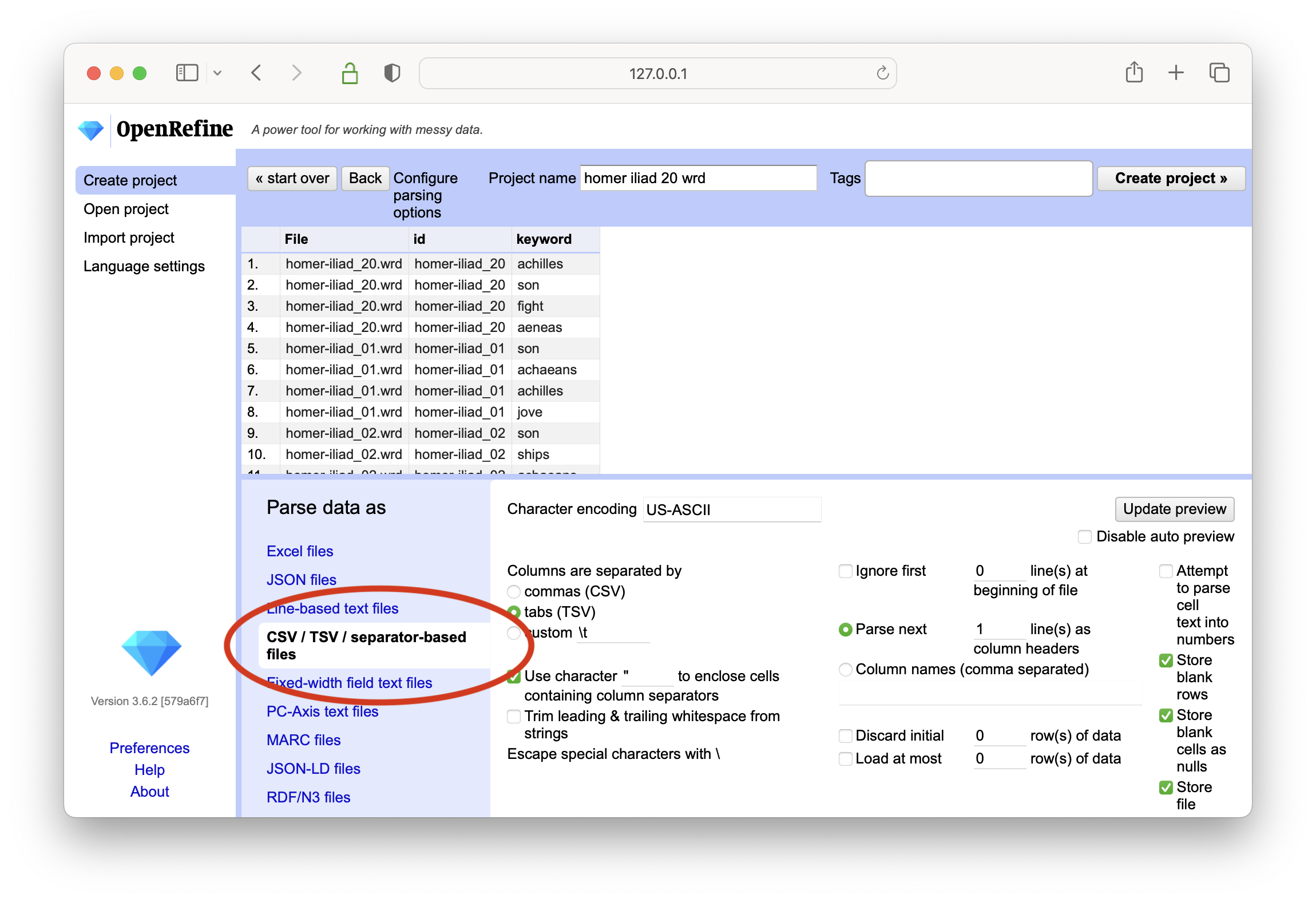
accept the defaults as you continue configure parsing and creating your OpenRefine project; remember that every file in the wrd directory is a tab-delimited file and you must use the “CSV / TSV / separater-based files” option to complete importing the data
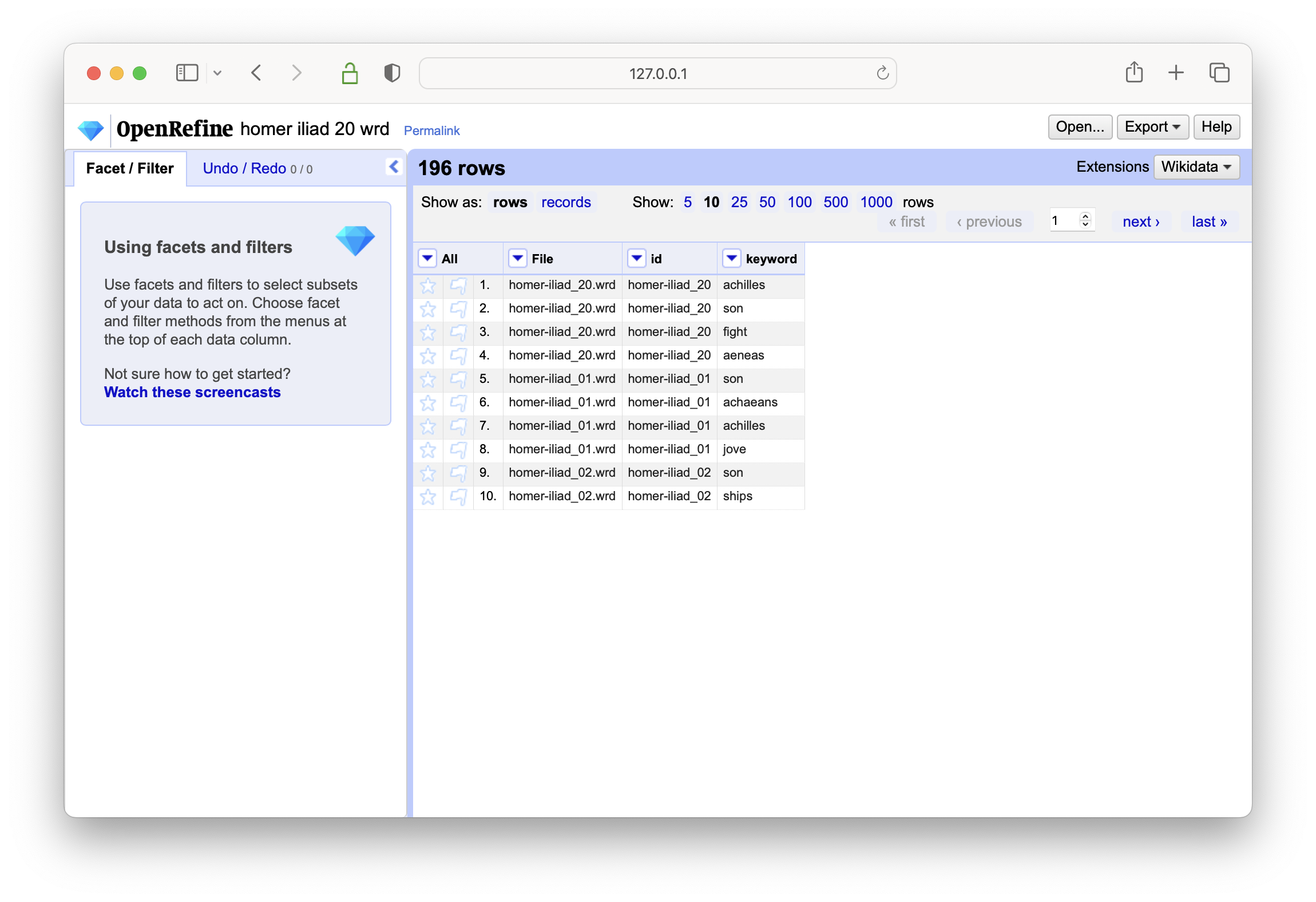
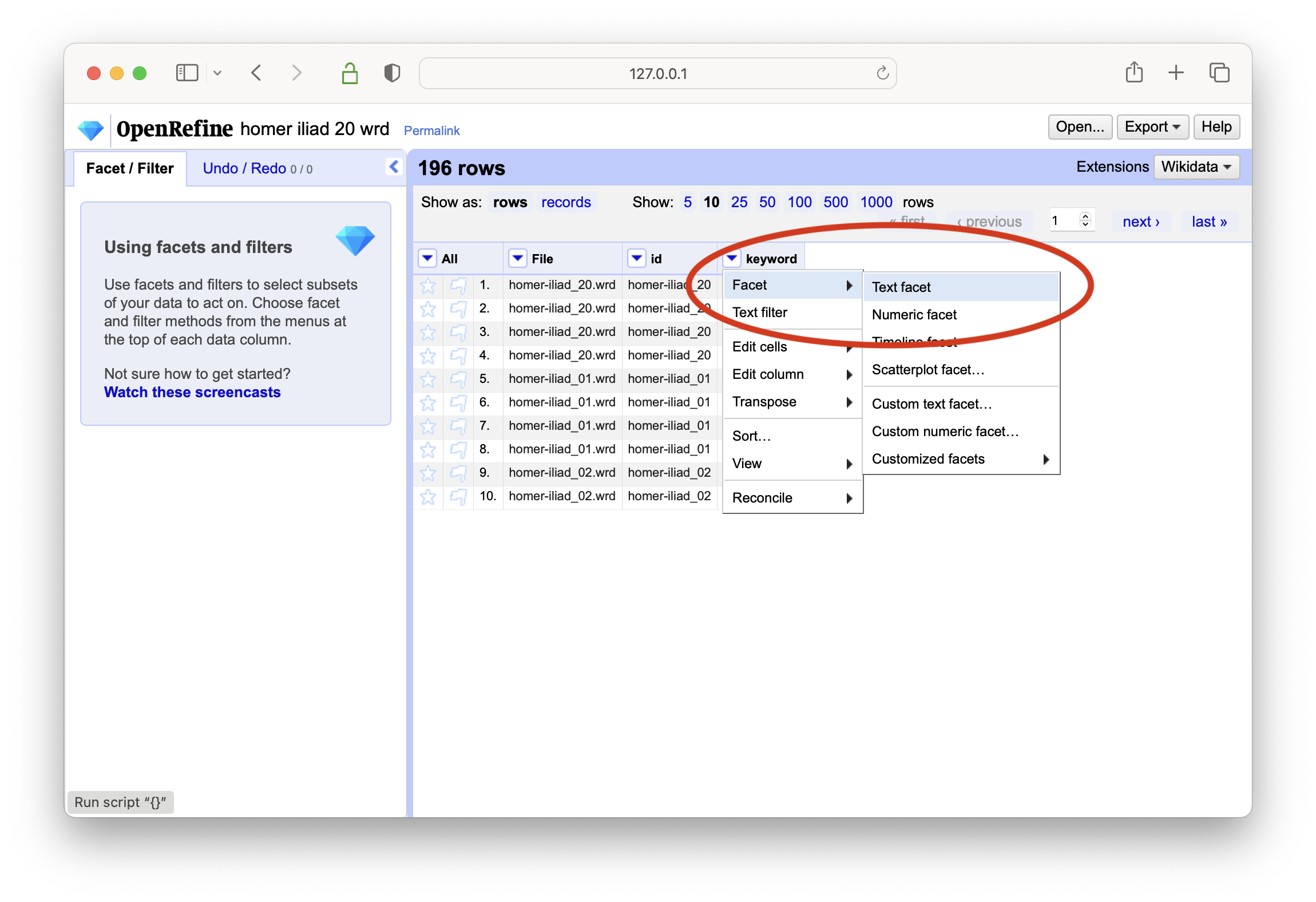
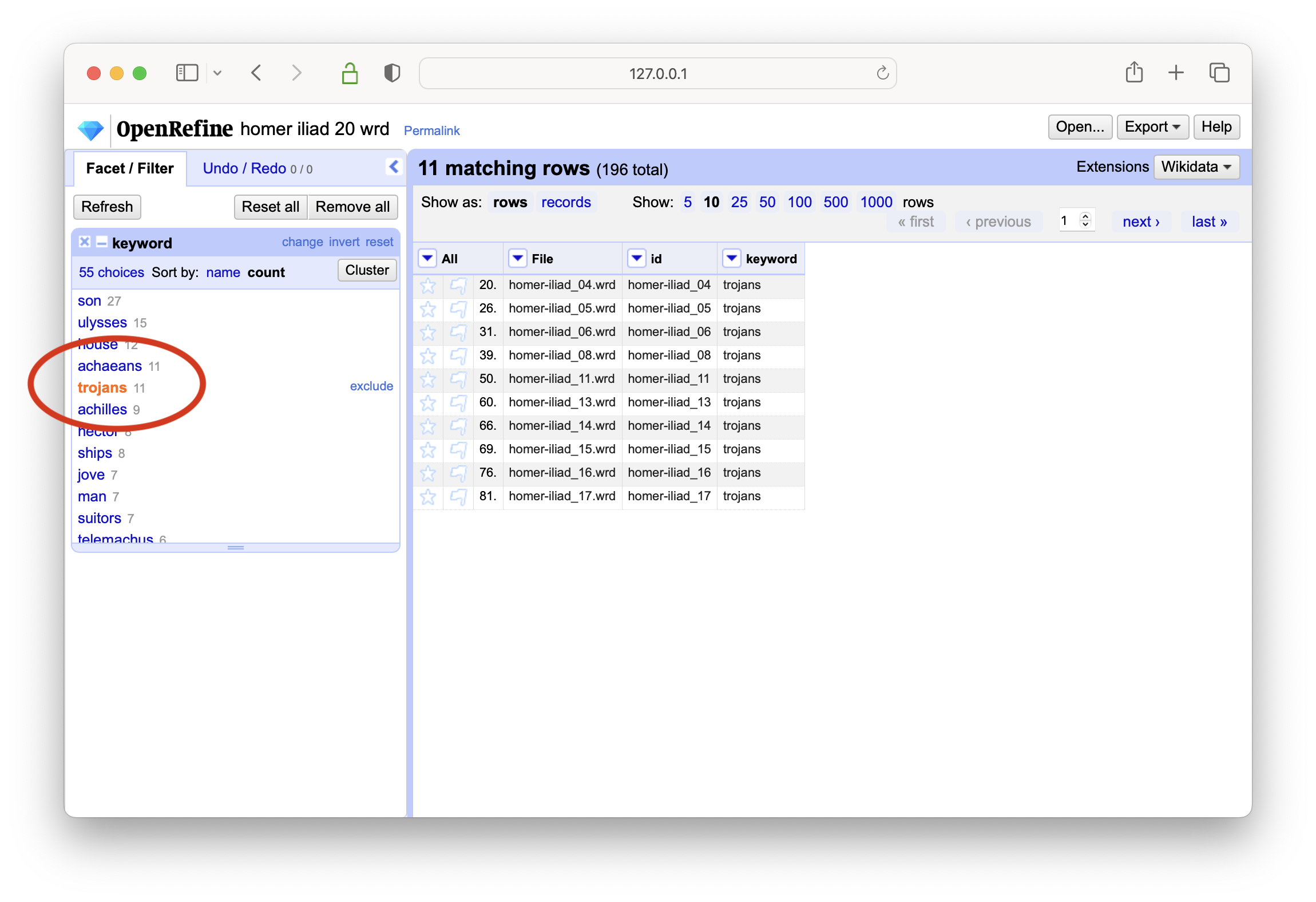
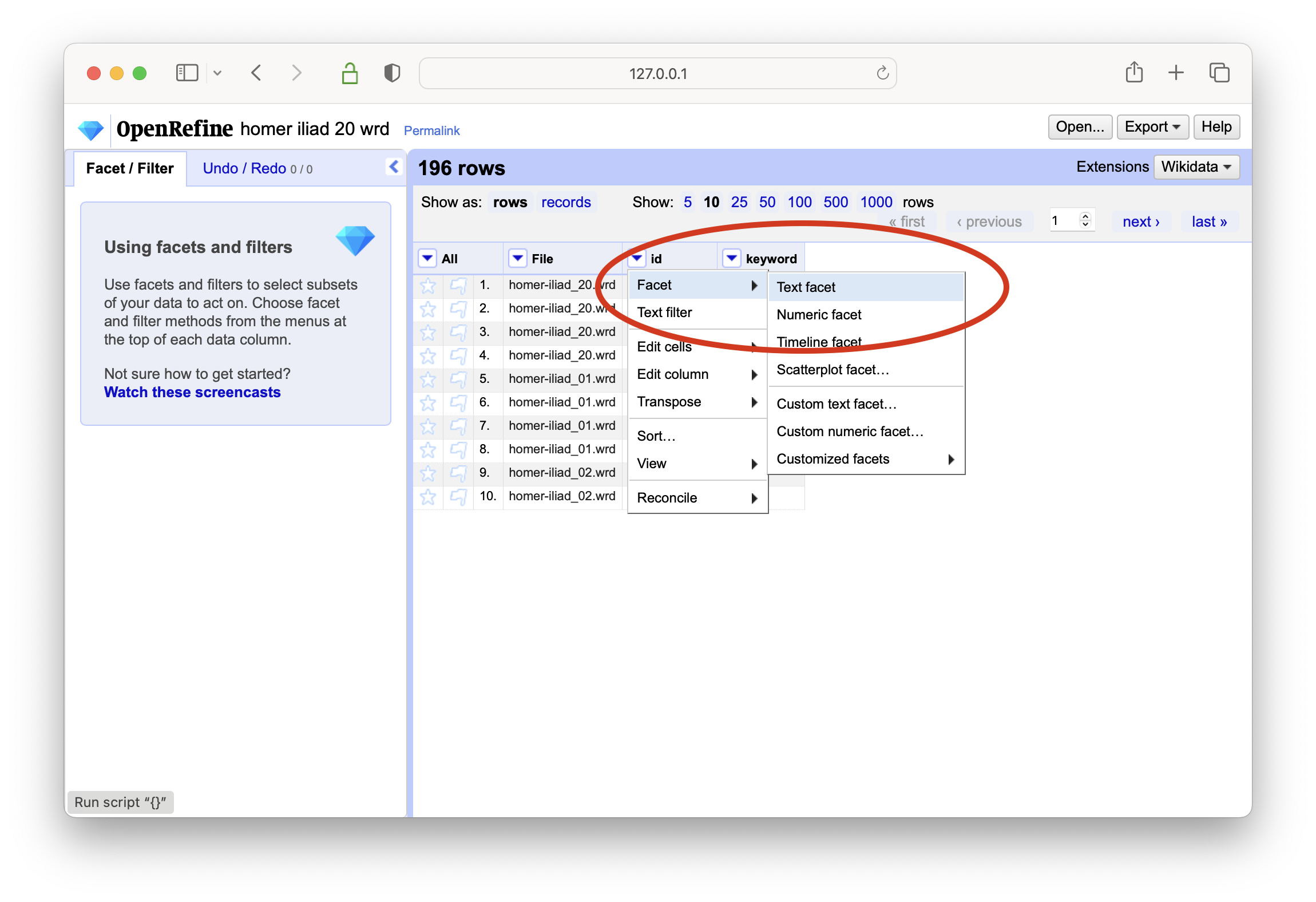
after the data has been imported, create a text-based facet on the keywords column
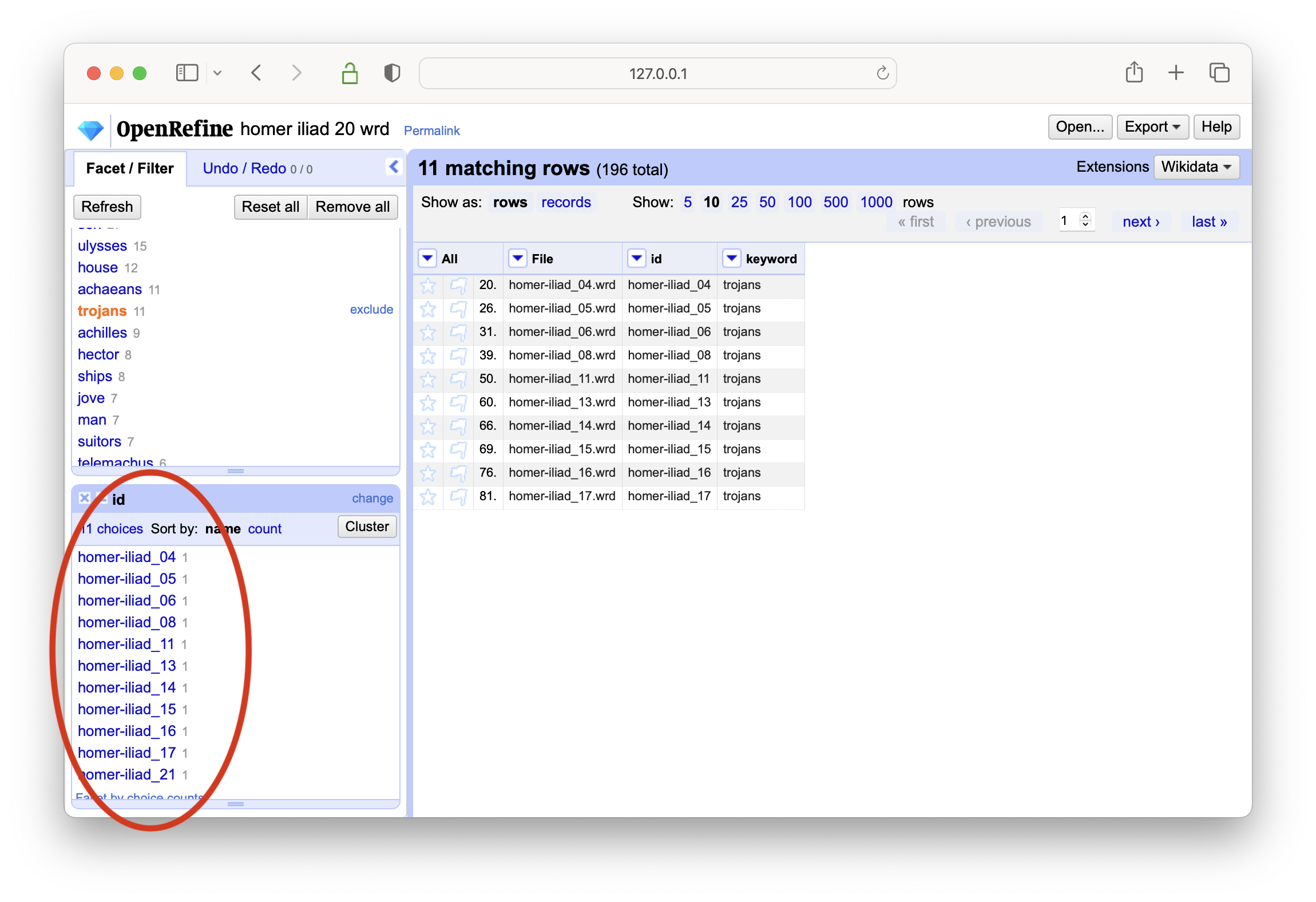
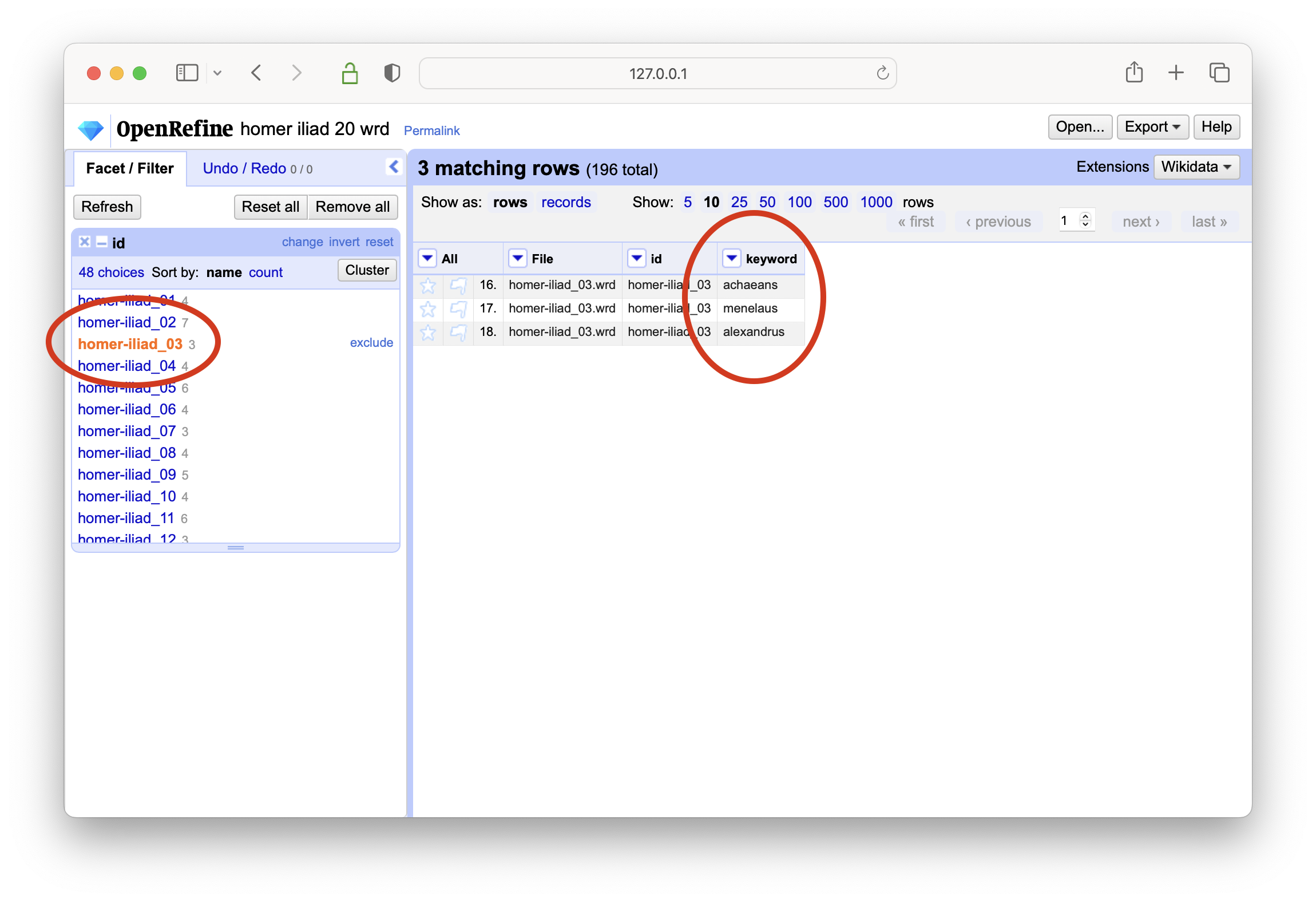
select a keyword of interest, and then create a text-based facet on the id column
in the end a list of identifiers will be displayed denoting which items in the carrel are about the selected keyword
select different keywords, and notice how the list of faceted identifiers changes
The same thing can be done the other way around, and you can ask yourself, “What is a given item about?” Here’s how:
use the Remove All button to return your project to the default state
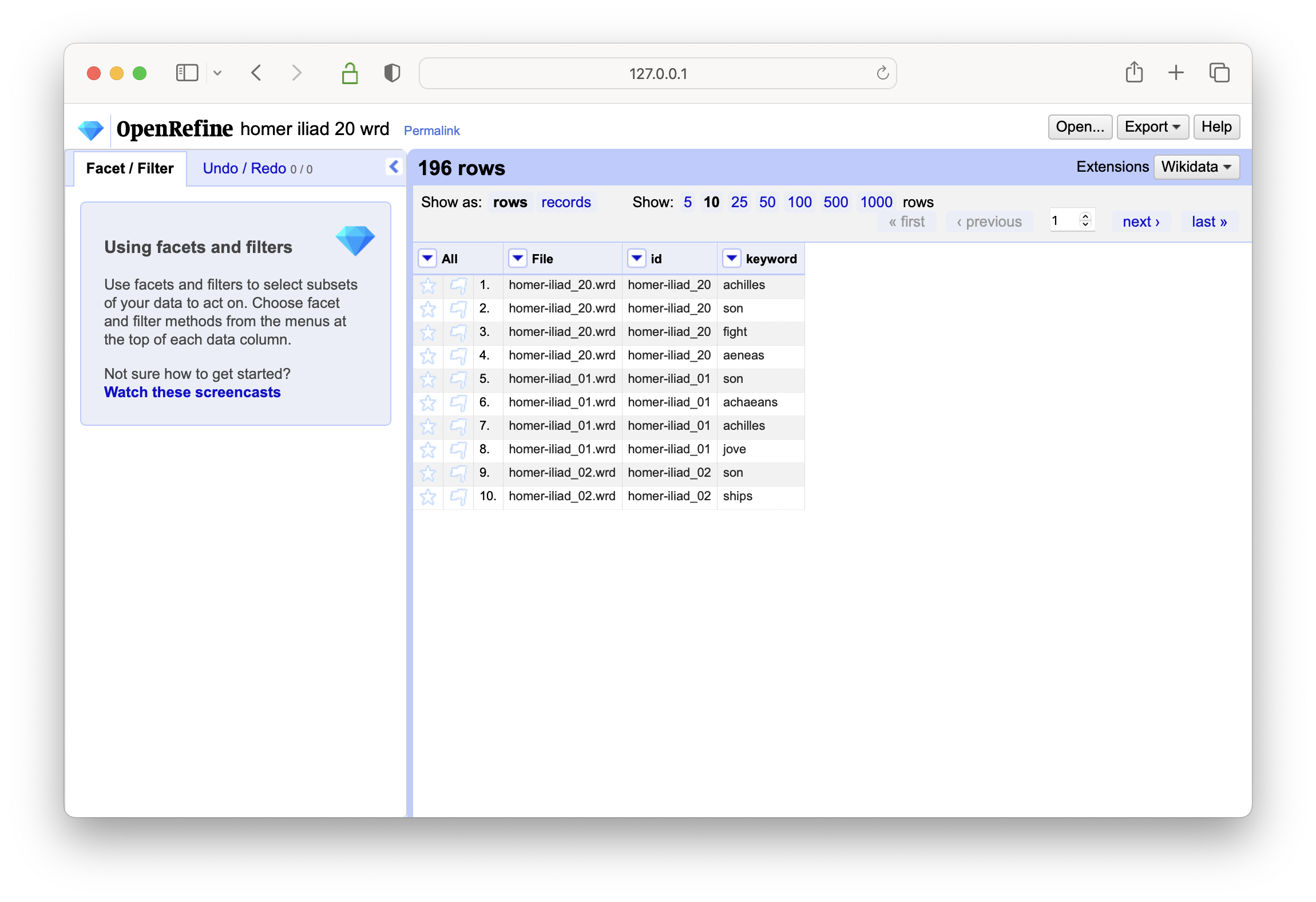
create a text-based facet on the id column
select an id of interest, and notice how the keywwords associated with the item are displayed
The tab-delimited files found in the wrd folder/directory are easy use because they contain a small number of columns with simple data types. The other delimited files are more complex, but by extension, they offer the ability to address more complex questions.
Named entities¶
The named enity files afford the ability to adress questions regarding people, places, organizations, and other things. Let’s address the question, “Who are the people mentioned in the Iliad and the Odyssey, and how often?” Here’s how:
use the Open… button to create a new project
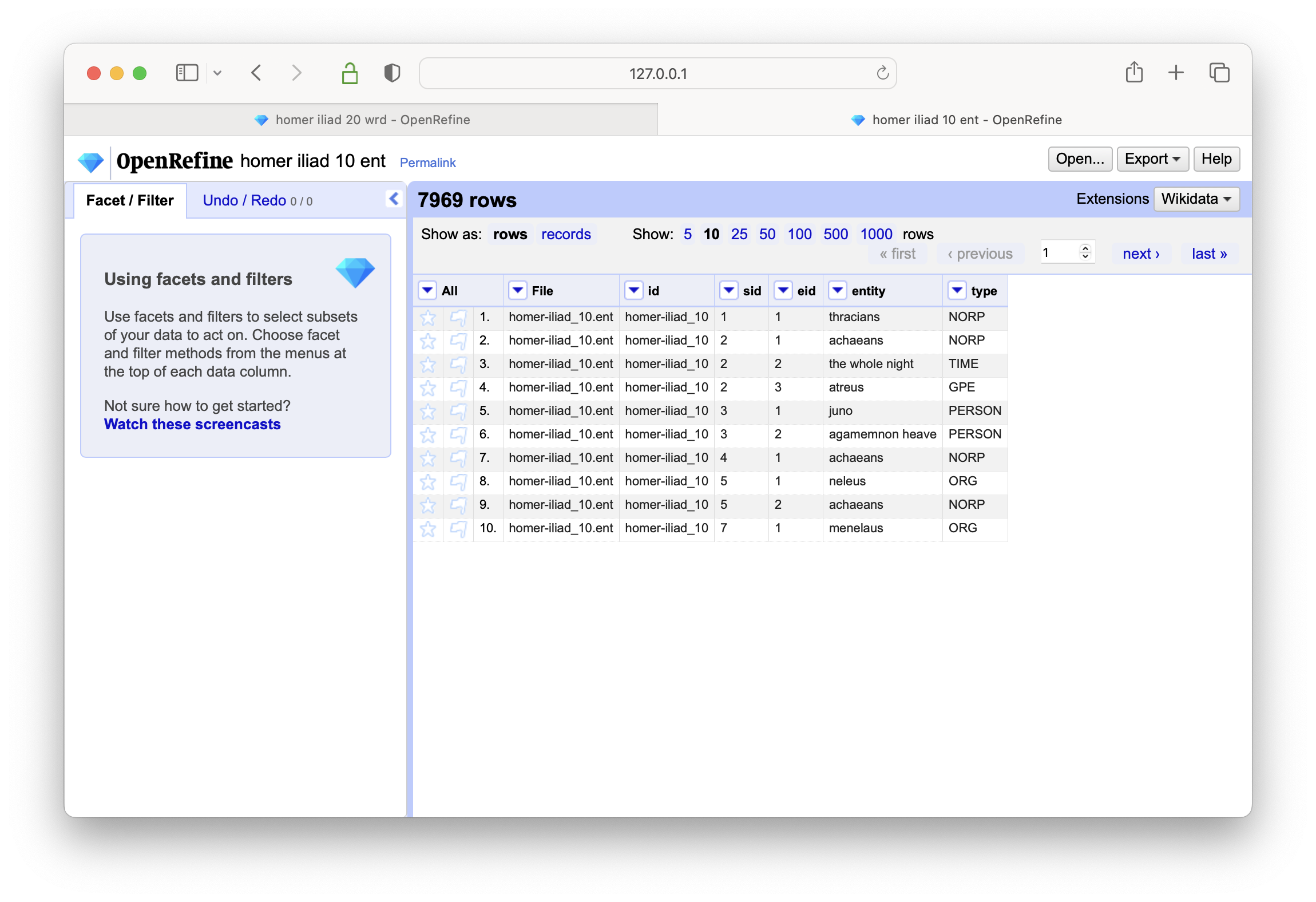
import all the files found the homer study carrel pos directory; remember that every file in the wrd directory is a tab-delimited file and you must use the “CSV / TSV / separater-based files” option to complete importing the data
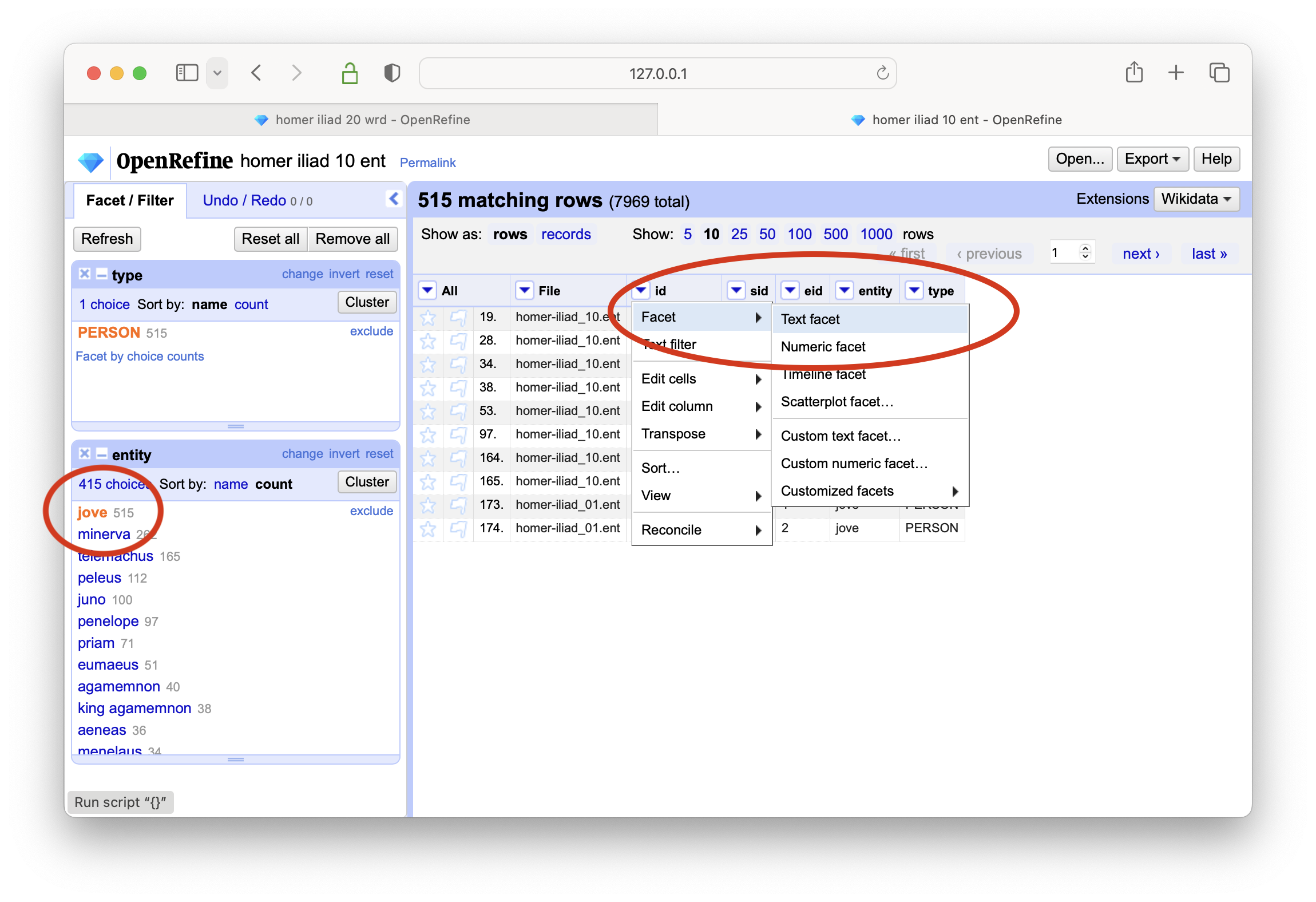
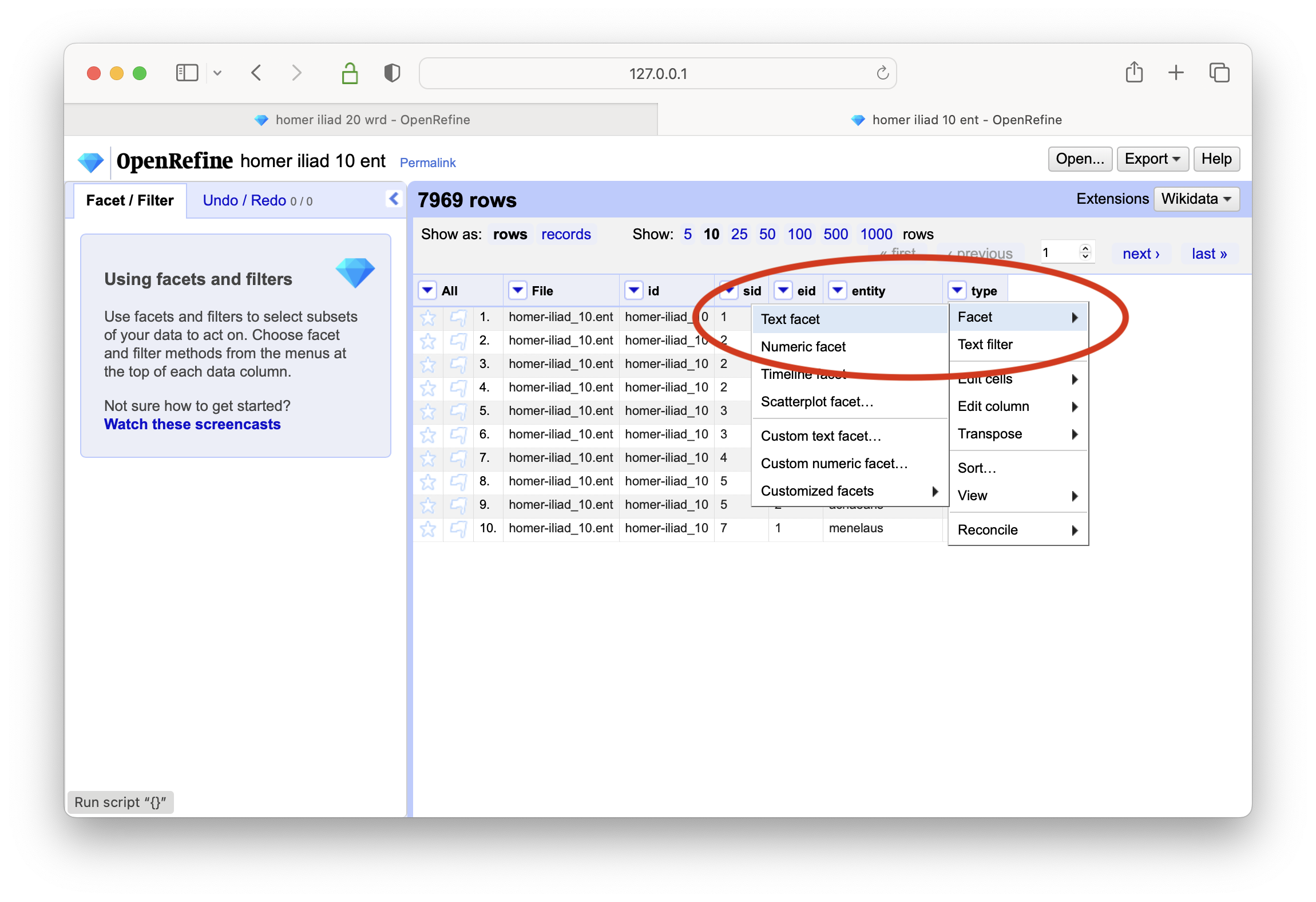
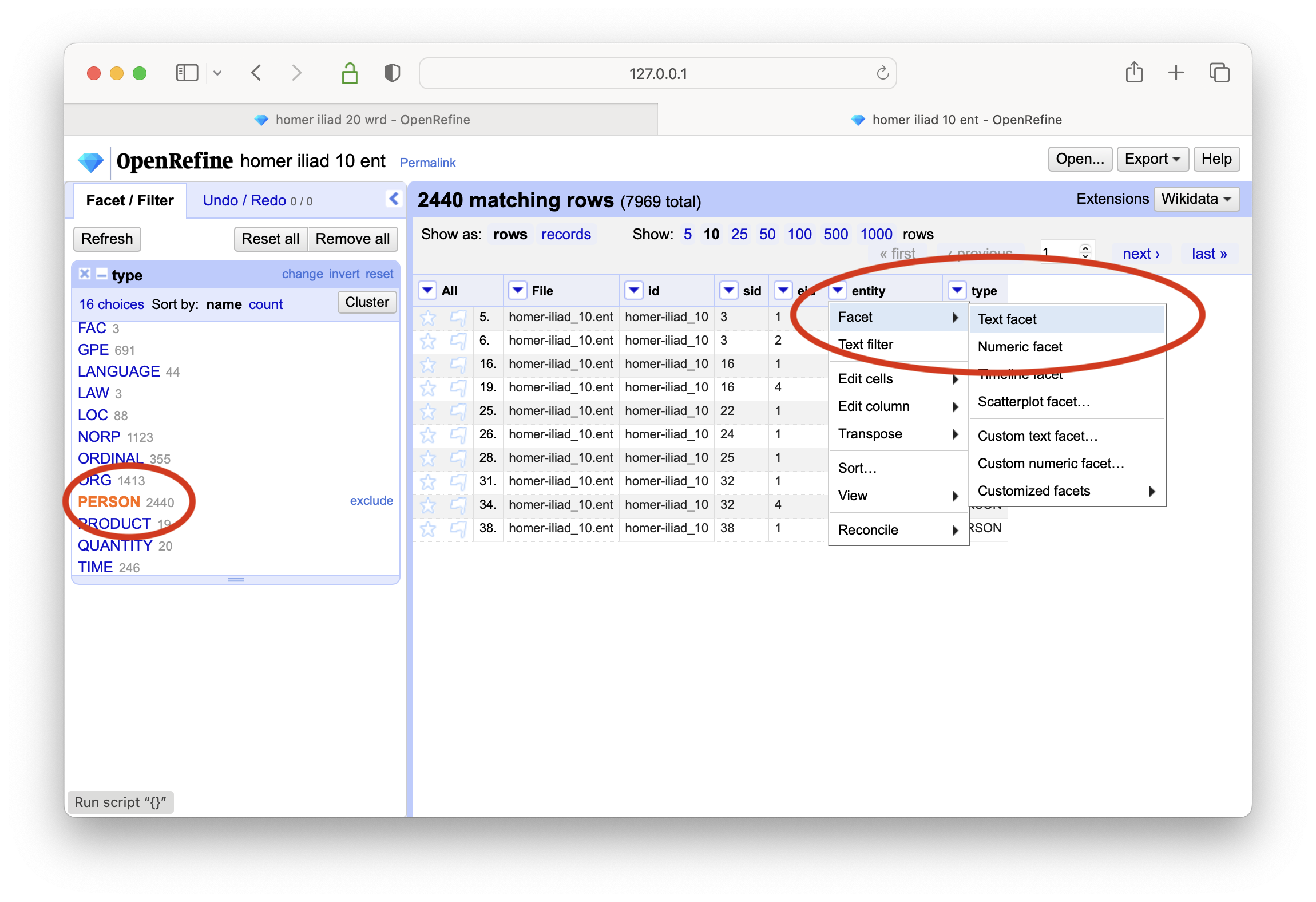
create a text-based facet on column named type
select the PERSON type, and create a text-based facet on the entity column
sort the result based on count, and the result addresses the question; Jove is the most frequently mentioned person
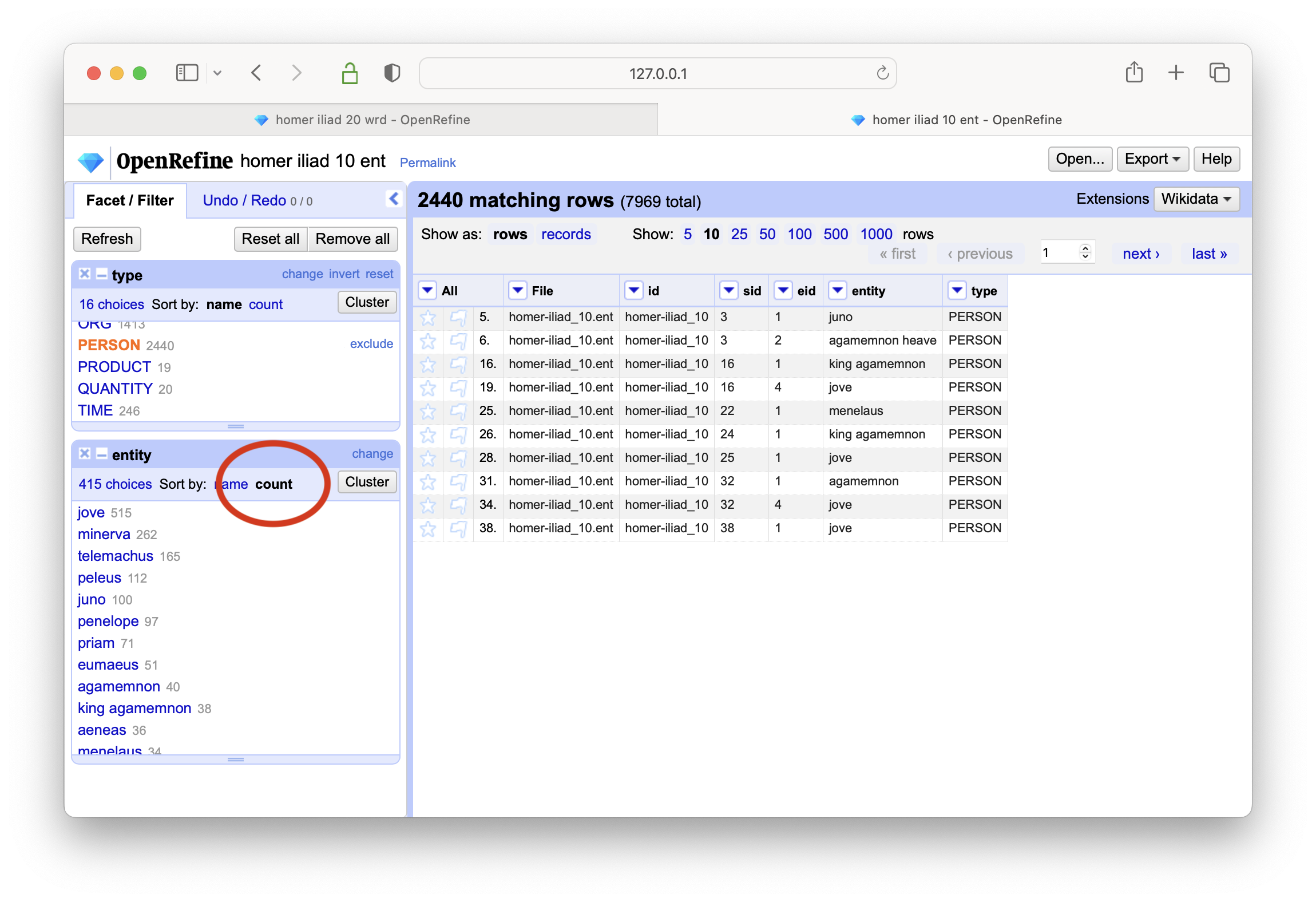
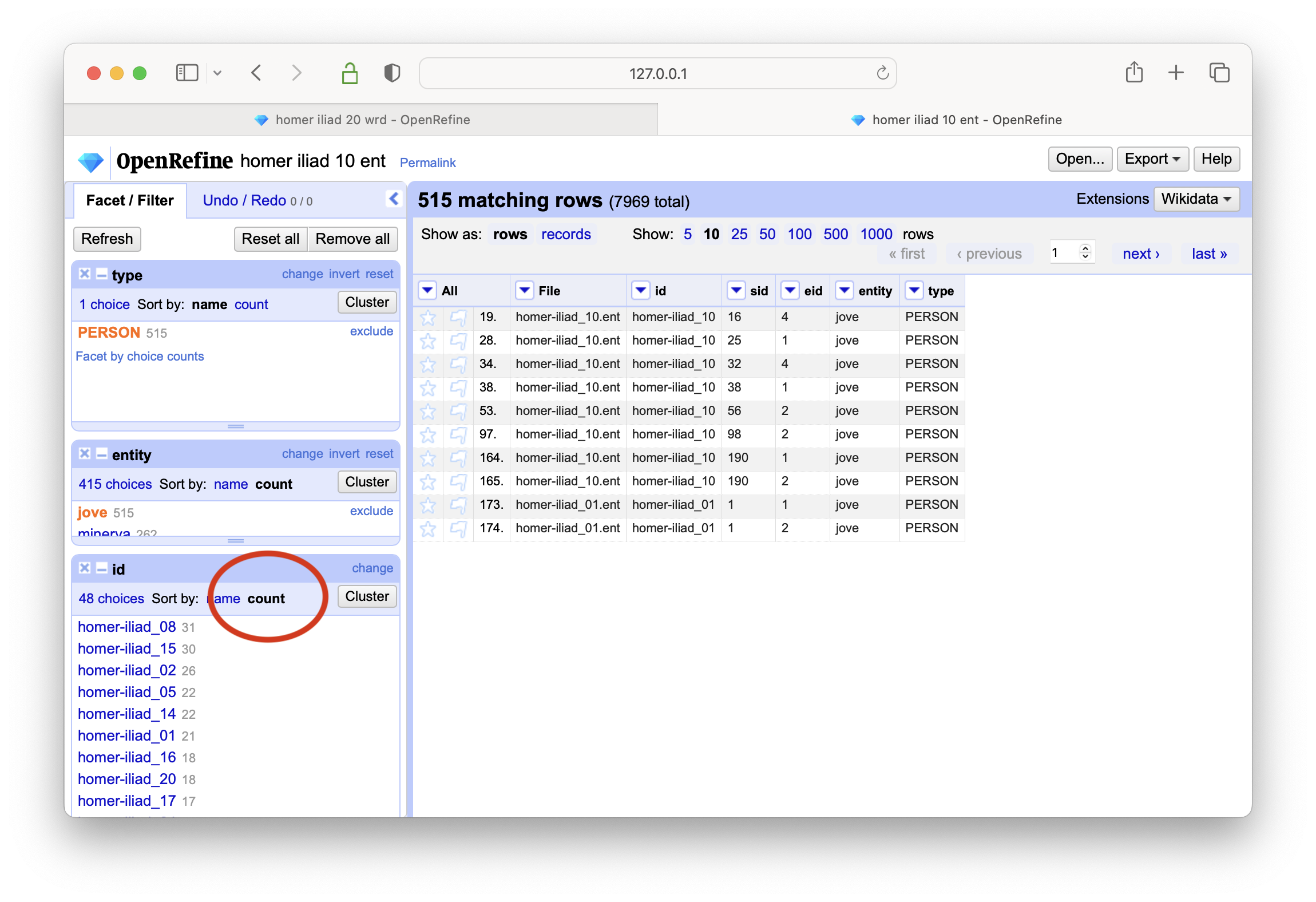
You can then ask, “In what items is Jove mentioned and how often?” To answer this question, you:
select a person of intered (Jove)
create a text-based facet on the id column
sort the result on count; Jove appears in many items, and he appears in the eigth book of the Iliad the most